Practical frontend architecture
Update: I felt this post needed a few points of clarification, so I added these at the bottom. If you’d like to skip there now, click here.
We’ve been upgrading our frontend tech stack at Liferay Cloud this past year. Nifty tools we’ve adopted include:
- React: easy componentization, commonly used, flexible
- Typescript: catch runtime errors at build, easy debugging
- Next.js: SSR by default, capable filesystem server, built-in SPA router, helpful docs
- Apollo GraphQL: commonly used (good docs), simple, automatic type generation ↗
We’ve also taken advantage of Tailwind.css and the Ant Design component library to speed up our development.
The RANT stack is a thing. Talking with other software engineers working on big frontend projects, React + Typescript + Next.js with a GraphQL solution is nothing novel, and for good reason. In my experience, it makes developing large sites with dynamic data a breeze, and it’s hard to name obvious limitations. The best-practices ↗ are well defined for each of these technologies and they’re only getting more popular ↗.
Using the right tools for the job is important. Using those tools in the right ways is equally as important, and that’s become a primary consideration on our team lately.
Considering architecture
It’s not often that software engineers get to make such fundamental decisions. Most of our time is rightly spent working with (and around) what we have. Rarely, we get to design systems that solve problems from the ground up. Those who architect buildings get points for elaborate creativity. Those who architect software get points for strictly fulfilling the requirements. Software architecture is practical architecture, not unlike Bauhaus. (The photo at the top is Ludwig Mies van der Rohe, famous for his pragmatic, “less is more” architecture.)
“The requirements” are vital. Single-page or multi-page application? Do we need SSR? Should our server code handle validation or just routing? How should an ideal initial pageload happen? All of these questions can be answered by considering “the requirements”. Rather than carry on about architecture principles, I’ll just share some of the thought process for our use-case at Liferay Cloud.
A dynamic dashboard
Our project is an enterprise-oriented dashboard for managing cloud services to run Liferay DXP Portal applications. It’s like Vercel ↗ for Liferay portals. As such, we must provide persistent authentication, display real-time dynamic data for each user, and rely heavily on backend services for updated content. We’d also like it to be easy and comfortable to use.
Like Vercel, we’ve created a single-page application with React + Next.js (which happens to be developed by Vercel). We’ve also elected to add a GraphQL layer to our primary API service using Apollo ↗ in order to optimize our fetching and take advantage of Apollo’s caching feature, which provides us similar benefits to Vercel’s SWR ↗ in terms of managing constantly-updated dynamic content. SPA and GraphQL+caching both fit our “dynamic dashboard” requirement perfectly.
Rendering
Next.js is well-known for being a “hybrid app framework”, meaning that it can be used to generate and serve websites with a mixture of statically-generated, server-rendered, and client-rendered pages. Static rendering is impractical for nearly all of our pages due to our dynamic requirements, so the decision was between SSR and CSR. While React applications are nearly always client-rendered, Next.js will actually attempt to render an application server-side by default.
Issues with Apollo + Next.js SSR
SSR-by-default is a highlight of Next.js, but it presents a non-ideal situation for server-side-rendered applications using Apollo, since there doesn’t appear to be a “comfortable” integration (yet) between Next.js and Apollo on the server-side.
Next.js’ “with-apollo” example ↗ requires developers to duplicate any Apollo queries that will happen within a given page’s initial render, including sub-components, on the getServerSideProps method in order to cache the response data on the server-side Apollo client instance. This cached data will then be “restored” into the Apollo client instance on the client-side so that it’s available for hydration ↗. The code duplication is frustrating, but even worse is having to maintain those query calls in multiple locations in the code (and two different paradigms, imperative and declarative) just to make them work. It’s incredibly discohesive and presents a scalability nightmare.
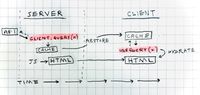
Apollo’s documented method ↗ abstracts away more of the complications but requires a double-render on the server-side. It uses an algorithm called getDataFromTree to render the page’s component tree a first time to collect and run all queries in the page (filling the cache). Then, the page is rendered again by Next.js so that it can be delivered as HTML and hydrated client-side with the cached data. This is nice because it removes the need for developers to maintain imperative duplicates of every query happening on a pageload, but it feels uneasy to knowingly double the render.
Implementing Apollo for strict client-side use is much simpler and doesn’t require duplicated logic or renders. Client-side Apollo is just straight-forward queries on each page, executed by the React engine during the client-side render. The code stays simple and predictable.
Rendering, practically
Don’t choose a microservices architecture just because it’s popular. ↗ Likewise, don’t choose server-side rendering just because it’s buzzy and sounds powerful. Server-side rendering does basically the same job as client-side rendering: generating HTML. The only real difference is that server-side rendering provides pre-rendered HTML to clients while client-side rendering requires the client to run JS files to render the HTML. This means that server-side rendering is ideal for websites that need strong search engine presence, since search engine bots can just read the static content immediately instead of possibly running into issues with JS content ↗. Server-side rendering is also necessary if clients have technical limitations, such as being unable to run JavaScript. Otherwise, server-side rendering is practically equal to client-side rendering.
CSR with Next.js
At Liferay Cloud, our project lives behind authentication and our clients are enterprise-level, with relatively modern browsers and powerful networks. So, SEO and client-side limitations are not concerns for us. Therefore, we’ve elected to render our application completely on the client. On Next.js this means that we wrap our React app in a “client-side only” component that looks like this:
const ClientSideOnly: React.FC = ({ children }) => (
<div suppressHydrationWarning>
{typeof window === 'undefined' ? null : children}
</div>
)
This component only allows our React code to render inside the browser environment, minimizing Next.js’ server-side render runtime. We can still run server-side code inside getServerSideProps to generate translated content or hide sensitive data from the client, but we don’t need to worry about any excess rendering happening on the server and affecting our TTFB.
The pageload
The logical steps behind an initial pageload on our app are (approximately) as follows:
- Is the route valid on the server? Next.js will automatically serve a
404if necessary. - Is the client authenticated? Else, redirect to
/login. - Does the user have permission to view the page? Else, redirect to a fallback.
- Are the route parameters valid? Else, show an appropriate error page.
- Are the data prerequisites for the page valid? For example, are we being asked to load a “feature X” detail page for an entity that doesn’t have “feature X”? Else, redirect to a fallback.
- Display skeletons and fetch data.
- Once data is available, render the page content.
Pageload validation
Seeing as step 5 (AKA, the “pageload validation”) is specific to a given page, we decided that this logic should exist either alongside or within the page it validates. Originally, we did this by adding a beforePageLoad method to each page which could be run prior to the pageload using a useEffect. That solution looked something like this:
types.ts:
export type CustomNextPage = NextPage & {
beforePageLoad: (
client: ApolloClient;
router: NextRouter;
) => Promise<void>;
}
MyPage.page.tsx:
const MyPage: CustomNextPage = ({ children }) => {
const { loading, data } = useQuery(QUERY);
if (loading) {
return <Skeletons />;
}
return (
<div>{data.value}</div>
);
};
MyPage.beforePageLoad = async (client, router) => {
const [data] = await client.query(QUERY);
if (!isValid(data)) {
router.replace('/redirect');
return false;
} else {
return true;
}
}
_app.page.tsx:
const App = ({ Component, pageProps }) => {
const { beforePageLoad } = Component as CustomNextPage;
const [isValid, setIsValid] = useState(false);
useEffect(() => {
(async () => {
const result = await beforePageLoad(client, router);
setIsValid(result);
})();
return () => setIsValid(false);
});
if (!isValid) {
return null;
}
return <Component {...pageProps} />;
}
Improving the pageload validation
We quickly noticed that we were duplicating our data fetches between the validation code and the actual page code, since the data needed for rendering the page was the exact data we needed to validate the pageload. So, we moved this validation logic into the page code itself by creating a useValidation hook for each page. This hook receives references to the data within the page code and returns a state variable which allows us to gate the render.
validation.ts:
export const useValidation = (data) => {
const router = useRouter();
const [isValid, setIsValid] = useState(false);
useEffect(() => {
if (!data) {
return;
}
if (isValid(data)) {
setIsValid(true);
} else {
router.replace('/redirect');
}
});
}
MyPage.page.tsx:
const MyPage: NextPage = ({ children }) => {
const { loading, data } = useQuery(QUERY);
const [isValid] = useValidation(data);
if (!isValid) {
return null;
}
if (loading) {
return <Skeletons />;
}
return (
<div>{data.value}</div>
);
}
This way, we don’t duplicate fetches and we allow the page code to concern itself with its own validation.
Unbranching the React runtime
Notice in the code above that we’ve been returning null in order to prevent flashing any unvalidated content to the user. This is tantamount to a branch in the React runtime, blocking the engine until we decide we can move forward. Why not just show skeletons the whole time? Wouldn’t that allow the React engine to render the page until the data is ready? Well, it would be awkward to show skeletons to the user and then redirect them once we realized the pageload was invalid. But it would be nice to stop blocking the React engine from rendering the layout. So, we found an alternate solution for hiding the render: CSS.
This idea ↗ comes straight from Guillermo Rauch, Vercel’s own CEO. Vercel’s dashboard site actually uses a :before pseudo-element to hide the HTML document while their app downloads and renders. Once the auth and validation complete, they add a CSS class called render to the document element. This render class hides the :before pseudo-element, revealing the page underneath. No unvalidated content has been flashed to the user and the React engine has been allowed to render the app freely behind the CSS veil.
We stole this idea for our project. We created a document-level pseudo-element to hide the page until everything is validated and we created callbacks to perform one of two actions: unveil or abort.
The unveil() callback simply adds the “unveil” class to the document element to hide the :before, just like Vercel’s render class. The abort() callback performs any necessary tasks when a pageload is considered invalid, such as redirecting the client to a fallback route. The abort() callback reference is re-instantiated on each route change in order to update its redirect logic according to the permissions spec for each page, that way the redirect is always correct based on the current route. Then, the useValidation hook can just call either unveil() or abort() depending on the validation result. No need to gate the render.
validation.ts:
const useValidation = (data) => {
const { abort, unveil } = useValidationCallbacks();
useEffect(() => {
if (!data) {
return;
}
if (isValid(data)) {
unveil();
} else {
abort();
}
});
}
MyPage.page.tsx:
const MyPage: NextPage = ({ children }) => {
const { loading, data } = useQuery(QUERY);
useValidation(data);
if (loading) {
return <Skeletons />;
}
return (
<div>{data.value}</div>
);
}
This allows the React engine to run freely behind the scenes and makes our page-level validation simple and declarative.
With these upgrades, the new logical steps behind an initial pageload on our app are as follows:
- Is the route valid on the server? Next.js will automatically serve a
404if necessary. - Is the client authenticated? Else, redirect to
/login. Page is hidden with CSS. - Does the user have permission to view the page? Else, redirect to a fallback. Page is still hidden.
- Are the route parameters valid? Else, show an appropriate error page. Page remains hidden.
- Begin running the page component, including fetching data and rendering skeletons. Still hidden.
- Are the data prerequisites for the page valid? Else, redirect to a fallback.
- Unveil the rendered page.
Custom error page logic
Note in step 4 of the pageload that we’re rendering an error page on demand if dynamic route parameters are invalid. For example, if a user attempts to access the route /items/12345/detail, this route implies that an “item” exists that can be identified as “12345”. But what if item 12345 doesn’t exist on the database? We don’t want to redirect the user to some fallback page; we want to show a 404.
Originally, we created more branching logic to handle this. We would set some boolean state to gate our render, perform a fetch operation in a useEffect, and then await the results to see if we needed to render an error page component. As it turns out, a much more elegant (and non-branching) solution exists: error boundaries ↗.
Instead of blocking our React runtime, we can create a component further up in our component tree that will act as an “error boundary”, catching errors that “bubble up” from nested components. If you’re familiar with event bubbling on the browser, the concept is similar.
If a component nested inside the error boundary component contains code which throws an Error, the error boundary component will catch the error when it fires its getDerivedStateFromError static method. From within that method, you can perform logic on the error boundary component to render an error page, log errors to the console, or anything else appropriate to the situation. If we wrap our whole page component in an error boundary, we can initiate an error page from any part of our page code, including our validation code, simply by throwing an Error.
Here’s an example of what this could look like:
error.ts:
export class PageError extends Error {
statusCode: number;
constructor(p: string, error: number) {
super(p);
this.statusCode = error;
}
}
ErrorBoundary.tsx:
class ErrorBoundary extends React.Component<{}, { errorCode?: number }> {
constructor(props: {}) {
super(props);
this.state = {
errorCode: undefined,
};
}
static getDerivedStateFromError(error: Error): { errorCode?: number } {
return { errorCode: error.statusCode };
}
render(): React.ReactNode {
if (this.state.errorCode === 404) {
return <404Page />;
}
return this.props.children;
}
}
MyPage.page.tsx:
const MyPage: CustomNextPage = ({ children }) => {
const { query: { itemId } } = useRouter();
if (!isValid(itemId)) {
throw new PageError(`Item ${itemId} not found`, 404);
}
return (
<div>content</div>
);
}
_app.page.tsx:
const App = ({ Component, pageProps }) => {
return (
<ErrorBoundary>
<Component {...pageProps} />
</ErrorBoundary>
);
}
The code above will render the 404Page component if the itemId route parameter is invalid, without using state and useEffect to create branching logic in the React runtime. It also enables us to execute wrapper-level code on the fly in case of a permissions issue, runtime bug, or any other case we want to handle.
Finishing this post
These are just some of the most notable patterns we’ve implemented lately. In the interest of keeping this post a readable length, that’s all for now. I have more to say on the topic of “practical frontend architecture”, particularly regarding use-cases that aren’t enterprise-oriented cloud dashboards, but I’ll keep organizing my thoughts and perhaps write more later on.
I hope you found something useful here. If you’re curious about anything or want to share your thoughts, feel free to email me at the address on my /about page.
Update: clarifications
This post made the front page of Hacker News, which was unexpected and fun. That means many people read and commented on what I wrote here. The commentary ↗ was constructive and refreshing, and brought up worthwhile questions and concerns. I thought I’d provide a few clarifications thereon:
Next.js is useful beyond SSR. A few reasons we still use Next.js at Liferay Cloud, despite disabling SSR:
- Flexibility to render non-dynamic pages statically, particularly non-auth pages like
/login. Most apps can benefit from hybrid rendering ↗. - Cohesive server-side code. Normally, server-side code exists in a separate monolithic server file or module-scoped controller file where it isn’t obviously related to the view code. In Next.js, this code lives in
getServerSideProps, right there in the page component. - Sensible defaults and inclusions, without cruft. Next.js is designed with “batteries included”, but doesn’t offer many tools that won’t be useful to nearly everyone. Conversely, Create React App is bloated ↗.
- Next.js is well-maintained and documented.
- A distraction-free dev experience designed with a “stay out of the way” and “just build” philosophy. As one Hacker News commenter wrote, “they keep the magic boundary at the right place”. A perfect example of this is their
<Head/>component, which enables easily adding page-specificheadtags without explicitly hoisting state.
In hindsight, this post is mistitled. Despite being called “Practical frontend architecture”, most of this post is about a few patterns we’ve implemented for our particular use-case at Liferay Cloud. I included some architecture-peripheral details, such as why we chose CSR, but I didn’t include many details on how we manage state, how the frontend relates to the server, project structure, etc. I’ll find opportunities to share more about all of these soon, but it should be known that this article would be better titled, “Some patterns we implemented recently, and a few architecture-related tidbits”.
Probably don’t copy and paste example code from blog posts. Somebody mentioned that I missed a few items in a useEffect dependency array. I’m a silly goose. Anyway, as a general principle, example code in a blog post is probably pseudo-code and probably contains bugs. But hey, if you’re feeling lucky, go for it. Just please don’t credit me in your commit.